
[Achtung, nicht alle Objekte auf dieser Seite sind im Sinne des https-Protokolls von sicheren Quellen.]
Es gibt neben Frames (siehe Artikel Mit fremden Federn) auch andere Möglichkeiten, fremde Inhalte in der eigenen Seite zu integrieren und die beiden farblich gekennzeichneten Zeilen zeigen ein Beispiel dafür. Zeile grün: aktueller Wechselkurs wird per JavaScript von einer fremden Seite geholt. Zeile rosa: statische Zeile.
JavaScript, die Lingua Franca des Internet, erlaubt den Import von Inhalten fremder Seiten. JavaScript erlaubt es, während des Ladens oder auch nach Interaktionen den Inhalt einer Seite zu verändern und durch fremde Inhalte aus anderen Dateien im Web zu ergänzen. Und auch bei JavaScript stellen wir gewisse Barrieren fest, die überwunden werden müssen. In einem reinen Html-Dokument stehen uns keine serverseitigen Sprachen wie PHP oder ASPX/C# zur Verfügung und daher muss man alle Aktivitäten in JavaScript erledigen.
Wenn man auf der eigenen Seite etwas zeigen möchte, was starken Schwankungen unterliegt – wie zum Beispiel ein Wechselkurs – dann ist die Angabe entweder falsch (weil veraltet) oder man muss den Text in ausreichend kurzen Intervallen editieren. Vernünftiger ist in einem solchen Fall, dass man diesen Wechselkurs von einer Seite holt, die den Kurs ihrerseits laufend aktualisiert. Genau das ist im obigen Beispiel in der ersten (grünen) Zeile geschehen. Die zweite (rote) Zeile enthält nur Text und daher stimmt der Wechselkurs nicht überein.
In den folgenden Beispielen wird Schritt für Schritt gezeigt, wie man die Technik entwickeln kann, mit der man die erste Zeile realisiert. Man muss bedenken, dass diese Seite eine WordPress-Seite ist und dass hier keine PlugIns verwendet werden sollen. Alles erfolgt mit Mitteln von JavaScript. Eine grundsätzlich Schwierigkeit besteht darin, dass Inhalte von http-Seiten auf einer Seite mit https-Protokoll nicht importiert werden können. Im Artikel relay.aspx, ein praktischer Trojaner wurde ein Programm vorgestellt, das die Barrieren zwischen https– und http-Webs überwindet und daher sind wir in der Lage, Seiten in diesem https-Web einzubinden, die auf einem http-Server liegt. Alle Beispiele in diesem Artikel liegen auf http://buero.clubcomputer.at. Würden wir diese Adresse direkt in einem JavaScript-Programm verwenden, würden diese Dateien in diesem Artikel nicht angezeigt werden. Daher werden sie so aufgerufen: /relay.aspx?target=buero.clubcomputer.at/mff/mff01.htm.
Der gewünschte Wechselkurs steht in der ersten Seite von Coinfinity und der dortige Code lautet:
[code lang=”xml”]
<span class="btc_price">2332,45</span>
[/code]
Man benötigt also ein Programm, das die Seite liest und die Zahl 2332,45 isoliert.
[code lang=”xml”]
<scr ipt src="/relay.aspx?target=http://buero.clubcomputer.at/mff/html.js" type="text/javascript"></scr ipt>
<div style="background-color: lime; text-align: center;"><em>Der aktuelle Kurs eines Bitcoin ist <b><span id="bitcoin"></span> €</b>.</em></div>
<scr ipt>
GetHtmlFileTag("/relay.aspx?target=https://coinfinity.co/", "bitcoin", "span", "class", "btc_price");
</scr ipt>
[/code]
Die erforderliche Hilfsfunktion GetHtmlFileTag stammt aus der Funktionsbibliothek html.js. Die Parameter sind von links nach rechts:
- Adresse des gewünschten Datums, hier
https://coinfinity.co/ - id des Tags, in das der Wert zu schreiben ist, hier “
bitcoin“ - Tagname des einschließenden Tags des gewünschten Datums, hier “
span“ - Attribut-Name, des den Tag näher spezifiziert, hier “
class“ - Attribut-Wert dieses speziellen Tag mit Attribut-Name, hier “
btc_price“
Die Funktion, die den gewünschten Wert aus der Web-Datei isoliert ist GetTag. Man sieht, dass mit Regex-Elementen das Muster gesucht wird und der eingeklammerte Ausdruck (.*?) liefert über arr[1] die Zahl zurück.
[code lang=”js”]
function GetTag(s, Tag, AttribName, AttribValue) {
var rx = new RegExp("<" + Tag + "\\s+" + AttribName + "=[‘|\"]" + AttribValue + "[‘|\"]>(.*?)<\/" + Tag + ">","gi")
var arr = rx.exec(s);
return arr[1];
}
[/code]
Text aus Programm
http://buero.clubcomputer.at/mff/mff01.htm
Um auf einer Webseite per Programm einen Inhalt einzufügen, benötigt man zunächst ein Ziel-Objekt. Im Allgemeinen ist das ein div– oder ein span-Tag und darüber hinaus ein JavaScript-Programm, das den gewünschten Inhalt holt und in dieses Tag einfügt.
Wenn man ein Programm veranlassen will, in dieses konkrete Tag etwas hineinzuschreiben, muss man es benennen. Entweder mit dem Attribut name oder mit dem Attribut id. Das Skript selbst benutzt das Objekt document und dessen Methode getElementById, um das Objekt target anzusprechen. Die Zeichen innerhalb des div-Tag finden sich in der Eigenschaft innerHTML und dieser Eigenschaft wird der gewünschte Text zugeordnet.
Das ist also die Art, wie man Texte zur Laufzeit (also im Zuge des Laden des Dokuments) eintragen kann. Das Dokument wird von oben nach unten “geparsed”, also abgearbeitet und daher kann das Objekt mit der id="target" erst angesprochen werden, nachdem es eingelesen wurde und daher muss der zugehörige Kode nach dem div-Tag stehen. Es gibt auch die Möglichkeit, diese Reihenfolge zu verändern aber das werden wir später sehen.
Das div-Tag kann sich irgendwo im Dokument befinden, also zum Beispiel kann es Teil einer Tabelle sein oder eine Bildunterschrift oder es kann auch mitten im Test stehen. Soll es Teil eines Fließtextes sein, dann muss man statt dem div-Tag das span-Tag verwenden, weil das span-Tag den Text nicht umbricht. Allerdings kann man diese voreingestellten Eigenschaften der Tags mittels Style-Sheets leicht verändern, es kann also durchaus sein, dass man einem div-Tag über das Style-Sheet mitteilt, dass vorher und nachher kein Zeilenumbruch stattfinden soll.
Dieser kurze Kode beschreibt also erst einmal, wie ein Text per Programm in ein Tag geschrieben wird.
Text von der Konsole
http://buero.clubcomputer.at/mff/mff01a.htm
Als Nächstes wollen wir den Text von der Konsole holen und zeigen. Im oberen Frame sieht man den Kode, im unteren Frame kann man den Kode ausprobieren. Ein eingegebener Text wird ohne neues Laden der Seite angezeigt.
Text von der Kommandozeile (QueryString)
http://buero.clubcomputer.at/mff/mff01b.htm?Text von der Kommandozeile
Wenn man eine Datei im Browser aufruft, dann folgen dem eigentlichen Dateinamen auch Variablen, die vom Dateinamen durch ein ‘?’ getrennt sind. Wenn man möchte, dass ein dort stehender Text auf der Seite eingefügt wird, kann man folgendes schreiben:
JavaScript ist objektorientiert aufgebaut und das Objekt window.location enthält in der Eigenschaft search. search ist alles, was rechts vom Dateinamen steht, inklusive des führenden Fragezeichens. Dieses Fragezeichen muss mit substring(1) entfernt werden, damit nur der Text daneben überbleibt. Wenn man aber Text mit Zwischenräumen oder auch Nicht-ASCII-Zeichen verwendet, werden diese Text in eine für das HTTP-Protokoll verträgliche Form umkodiert und diese Kodierung wird mit der in JavaScript eingebauten Funktion decodeURIComponent wieder rückgängig gemacht.
Text aus Datei
Wenn wir “Datei” sagen, dann meinen wir nicht eine Datei im Windows-Datei-System sondern eine Datei auf einem Server. JavaScript kann auf das Windows- (oder Linux-)dateisystem nicht zugreifen (auch wenn das hier den Anschein hat) sondern es kann nur eine Datei von einem Server anfordern. In diesem Fall heißt die Datei mff02.txt. Da nur ein Dateiname angegeben ist, ergänzt der Server diesen Dateinamen zu einer vollständigen Internet-Adresse. Wenn sich also die rufende Datei mff02.htm auf dem Server buero.clubcomputer.at im Verzeichnis /mff befindet, macht der Server daraus https://buero.clubcomputer.at/mff/mff02.txt.
Für solche Requests von Webinhalten gibt es in JavaScript das Objekt XMLHttpRequest. Wie man damit umgeht, erfährt man zum Beispiel bei W3Schools. Der Aufruf ist aber ein bisschen komplizierter als wird das vom Dateisystem her kennen. Es gibt nämlich zwei verschiedene Aufrufformen: synchron oder asynchron. synchron entspricht einem Aufruf im Dateisystem. Das Programm verweilt so lange, bis der externe Inhalt geholt ist. Das kann aber im Internet – je nach Verbindung – durchaus eine zeitlang dauernd und während dieser Zeit wird nichts weiter getan als gewartet, was für einen Besucher einer Seite oft lästig ist. Daher wird praktisch nur die Aufrufvariante “asynchron” verwendet, in der man den Auftrag zum Holen der Datei gibt und dazu sagt, was nach Beendigung zu tun ist. Inzwischen wir am Seitenaufbau weiter gearbeitet.
Asynchrones Laden eines Objekts
http://buero.clubcomputer.at/mff/mff02.htm?mff02.txt
Man öffnet eine Datei mit xmlhttp.open() mit der Methode GET und asynchron, was durch das dritte Argument true angekündigt wird. Den Dateinamen tragen wir nicht fest ein, damit wir dasselbe Programm mit verschiedenen Dateitypen und Adressformen testen können. Das erfolgreiche Ende asynchroner Aufrufe wird durch die Abfrage des Status erkannt.
Um das Programm zu testen, geben wir die Programmadresse ein:
(1) http://buero.clubcomputer.at/mff/mff02.htm
(2) http://buero.clubcomputer.at/mff/mff02.htm?mff02.txt
(3) http://buero.clubcomputer.at/mff/mff02.htm?http://www.illsinger.at/wordpress/license.txt
(4) http://buero.clubcomputer.at/mff/mff02.htm?http://fiala.cc/license.txt
(5) http://buero.clubcomputer.at/mff/mff02.htm?/relay.aspx?target=http://www.illsinger.at/wordpress/license.txt
(1) Kein Parameter, daher keine Anzeige
(2) lokale Datei mff02.txt wird angezeigt
(3) keine Anzeige
(4) Lizenzbestimmungen von WordPress werden angezeigt
(5) Lizenzbestimmungen von WordPress werden angezeigt
Im Punkt (3) und (4) werden zwei Word-Press-Websites angesprochen und zwar jeweils die Datei license.txt, die sich normalerweise in jedem WordPress-Web befindet. Richtig ist, dass – wie im Punkt (3) nichts angezeigt wird, denn JavaScript kann diese Datei nicht lesen, weil nur der Zugriff auf lokale Dateien erlaubt ist und man diese durch die Angabe der relativen Pfades ansprechen kann wie im Beispiel (2).
Warum aber sieht man den Text aber im Beispiel (4)? Der Grund ist folgender: Im Grundzustand kann das Objekt XMLHttpRequest Daten von fremden Servern nicht lesen. Man muss die rufende Seite autorisieren, damit das möglich ist. Dazu muss die gerufene Seite den HTTP-Header den Namen AccessControl-Allow-Origin enthalten und dessen Wert muss * oder den Namen der zugelassenen Domäne haben.
Damit aber (5) funktioniert, muss man noch einen Wert in der Datei web.config ändern, sonst bekommt man eine Fehlermeldung wegen der verdächtigen Zeichen im QueryString (Etwa kommt das Fragezeichen zwei Mal vor).
[code lang=”xml”]
<system.web>
<httpRuntime targetFramework="4.5" requestPathInvalidCharacters="" />
</system.web>
[/code]
Das folgende Bild zeigt, wie man im WebSite Panel einen zusätzlichen Header in einer Webseite hinzufügt:
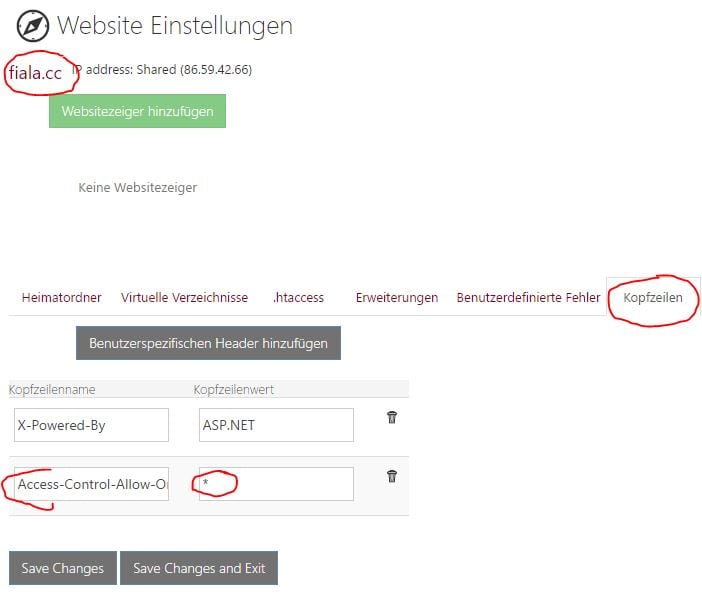
Die konzeptuell vorgesehene Lösung ist also die, dass man mit der Seite, die den Inhalt zur Verfügung stellt, über einen Header-Namen den Zugriff erlaubt. Erinnern wir uns aber an die Datei relay.aspx, die dazu gedient hat, beliebige WebAdressen anzusprechen und deren Inhalt an lokalen Inhalt anzuzeigen. Diese Datei relay.aspx wird im Beispiel (5) angewendet, um dem fremden Server zu überlisten und die dortige Lizenz-Datei dennoch anzuzeigen. und warum ist das so? Der Grund ist, dass relay.aspx die Datei so holt wie das ein Browser üblicherweise tut aber ein JavaScript-Programm die Header berücksichtigt und daher der Zugriff eventuell eingeschränkt wird.
Was tun mit dem fremden Kode?
Wir erhalten bei Anforderung einer Html-Seite aus dem Internet immer eine komplette Seite mit Kopf, Menüs usw. Wenn man aber Inhalt von einer fremden Seite einbetten will, dann immer nur einen Teil davon. Praktisch nie wird man zum Beispiel den head– und den body-Tag einbetten, weil dann diese Tags im eigenen Kode doppelt vorkommen würden. Man muss also die gewünschten Details isolieren; entweder den HTML-Text nach den gesuchten Tags durchsuchen, also beispielsweise mit Regex-Suchen/Ersetzen oder man kann das Html-Dokument als DOM-Objekt betrachten und mit den Mitteln der Methoden des DOM nach den Inhalten suchen. Nach zahlreichen Versuchen kann ich berichten, dass die Suchfunktionen mit Regex-Ausdrücken immer funktionieren und die Auswahl der Seitenobjekte mit dem DOM sehr oft keine Ergebnisse liefert.
Isolieren mit Regex
Um sinnvolle Daten aus einer Html-Seite zu isolieren, muss man die Html-Datei in ein Fragment verwandeln und folgendes entfernen: Kopfteil inklusive Body-Tag, Scripts, Styles, Attribute (aber nicht in Bildern oder Links). Für jede einzelne Aufgabe schreiben wir eine Funktion und kombinieren alles mit der asynchronen Lesefunktion. Weiter muss man berücksichtigen, dass alle diese Filter optional sein sollten. Dazu gehören Funktionen, dass man den Inhalt nur aus einem bestimmten Element extrahiert oder nur den Inhalt zwischen Markierungen. Alle diese Funktionen kommen in eine Datei html.js, die bei Bedarf in eine Html-Datei importiert wird. Angewendet werden diese Funktionen so: in der Html-Datei gibt es ein Tag, in das die externen Daten einzubetten sind. Wir werden dafür ein div-Tag. Danach gibt es eine Funktion WriteHtml(), die den gewünschten Inhalt in das Tag einfügt:
Am anschaulichsten ist es, wenn man das Test-Programm studiert, weil damit immer der Original-Kode mit dem durch den Filter veränderten Kode verglichen wird.
Hilfsfunktionen
http://buero.clubcomputer.at/mff/html.js
Testprogramm
http://buero.clubcomputer.at/mff/html_test.html
Testdaten
http://buero.clubcomputer.at/mff/html_test_daten.html
Die hier gezeigten Programme sind in laufender Bearbeitung und können sich daher immer wieder auch ändern.
Neueste Kommentare